
Nana Hou
Contact:
nanahou1123@gmail.com
I am an Audio AI Engineer at Zoom working on expressive text-to-speech, audio deepfake detection, and real-time speech enhancement.
💡 Read my latest blog post: Nana's Audio AI Log!
I received my Ph.D. in Computer Science from Nanyang Technological University and my B.Sc. from Sichuan University.
Publications [Blog] [Google Scholar]
* indicates equal contribution

|
SEA-Spoof: Bridging The Gap in Multilingual Audio Deepfake Detection for South-East Asian
|
|
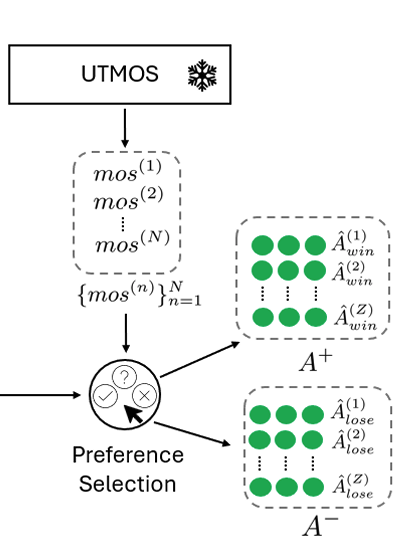
Aligning Generative Speech Enhancement with Human Preferences via Direct Preference Optimization
|
|
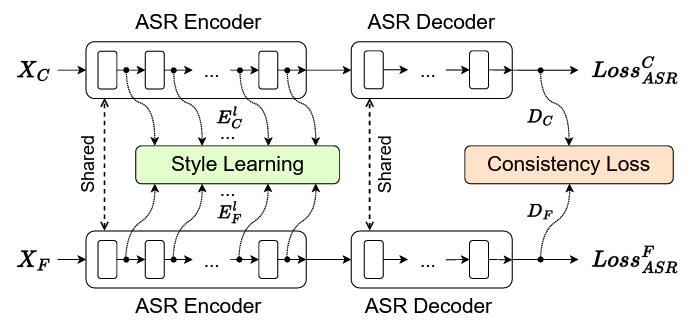
Dual-path style learning for end-to-end noise-robust speech recognition
|
Academic Service
- Conference reviewer: ICASSP, INTERSPEECH, AAAI, etc.